
About the Newton Project
1. Introduction
Formed in 1998 under the general editorship of Rob Iliffe and Scott Mandelbrote, the Newton Project set out to produce a comprehensive edition of Isaac Newton’s ‘non-scientific’ papers. Since 2007 it has expanded its aims so that its chief goal is to produce a comprehensive edition of all of Newton’s printed and unpublished writings. The project team is currently based at the Faculty of History, University of Oxford. and its core functions have been directed since 1999 by Iliffe. From 2008 to 2014 the project was funded by two major Arts and Humanities Research Council (AHRC) Research Grants and two Joint Information Systems Committee (JISC) awards. Private funders have also made generous donations to the project, without which the transcription of the scientific and mathematical papers would have been impossible. The Newton Project could not have achieved its goals without major collaborative work undertaken with the Chymistry of Isaac Newton Project at Indiana University; the Newton Project Canada at King’s College, Halifax, Nova Scotia; the Cambridge University Digital Library (CUDL); and the National Library of Israel (NLI).[1]
Since January 2008 The Project has published over four million words of diplomatically transcribed text, about 90% of which is made up of Newton’s technically forbidding writings in physics, mathematics and theology. These are foundational documents in Western and indeed global intellectual history, and they are published in full, with accompanying images of the originals, for the first time. The amount of text published during this period is almost double the output attained up to the end of 2007, and the rate of production has been achieved thanks to the successful completion of the four major research grants held during the period. Given the complexity of the documents and the scale of the task, the transcription and encoding of all the religious papers, about 95% of which is now available online, represents a remarkable achievement. No other comparable body of previously unpublished religious documents has been released online, and the detailed coding of the born-digital scientific and mathematical texts is unrivalled for a project of this scale. Indeed, the writings on the exact sciences published on the Newton Project’s website constitute some of the most complex body of documents transcribed with a combination of MathML and TEI-P5 encoding.[2]
2. The Newton Project as a Scholarly Edition
Apart from the transcriptions of the various editions of Principia and Opticks, all the documents authored by Newton published in the current REF cycle have been produced from manuscript sources. The rendition in a diplomatic/normalized form of the heavily overwritten religious texts and the complex scientific and mathematical works have forced the Project to push to the limits the potential of the frameworks provided by the latest instantiation of the Text Encoding Initiative Guidelines ( TEI-P5) and MathML. At the top of each text researchers can now see the date and process of online publication of each document (its ‘revision history’), and advanced users can now see the schema and XML coding that undergird the digital document. Where possible, documents have contextual material in the form of catalogue details, translations into English, and links to images of original documents. A general introduction to the documents is provided in the following section. The texts are freely available to the general public, a feature that offers significant benefits in terms of outreach and the potential for future crowdsourcing.
The digital medium is particularly appropriate for hosting the writings of a man who evinced what can only be described as a visceral hatred for print culture. Although his interest and expertise in both church history and prophecy was known to many people, no print edition of any of his non-scientific writings, authorized or otherwise by Newton, appeared in his lifetime (though he did show selected works to acolytes). His research remained constantly work-in-progress and there was no terminus to his various projects in the form of truly ‘final’ treatise (this of course applies equally to his great printed works). An evolving and expanding digital site is eminently suitable for publishing these private researches, for showing them to their full extent, and for representing the detailed and dynamic process of his thought.[3]
Increasing scholarly attention has recently been focussed on ways of classifying different sorts of ‘digital’ output. One concern of these discussions has been the question of whether digital editing takes a different form, or has different goals from conventional editing. The response to this issue can depend on how generally one conceives of the task of editing. If it is supposed to concern the production of some sort of introductory or contextual information about the document and the text, then obviously the goals of print and digital editing are similar. However, there are special, distinctive aspects of editions that are hosted online (as opposed to being on CD-ROMs), and in particular, of datasets whose core content is either born-digital text or non-textual data (such as film or music). These features concern, inter alia, the manner in which the information is acquired, stored and displayed, the size and complexity of the dataset in question, the nature of the IP agreements required to publish texts in perpetuity, and the potential audiences for the output. It is of course, a peculiar quality of digital text that it can function both as an end-in-itself, i.e., act as a linear narrative that can be read as one would read a print narrative, and also as a searchable dataset.[4] The last point is central to understanding the relationship between the logic of production and the needs of the audience, since scholarly users of the site have invariably preferred that the Newton Project concentrate its energies on the release of searchable text. It should not be forgotten that almost none of the religious materials the Newton Project has released since the start of 2008 has previously been seen by more than handful of scholars.[5]
Recent literature points to a distinctions between a digital ‘edition’, a digital ‘archive’, and a digital ‘research environment’, though there is substantial disagreement over what these terms denote, and whether they can be clearly distinguished from each other. I assume here that a proper digital archive contains a full diplomatic rendition of a collection of documents, with a comprehensive underlying encoding that can be scrutinised by readers if they so wish. Ideally, this should also allow readers easy access to very good quality images of the original document, though financial, copyright, technical or other reasons may make the provision of these difficult or impossible. On its own, the presentation of images without transcriptions does not count as a digital archive, though for very large datasets, searchable collections consisting of images encoded with basic metadata may be ‘good enough’ for research purposes (and some digitised images of printed materials can be searched on the fly). Transcriptions in a properly constituted digital archive should have been encoded and proofed to the highest standards, while differences in interpretation of difficult passages that occur at various stages of the checking process should be preserved in code.
One conception of a digital archive is that it is an environment in which the researcher is given direct access to the images and/or transcriptions of the original materials, as if he or she were actually in the presence of the documents. This constitutes the pure antithesis of the situation in print culture, where a number of different aspects of the material edition reinforce its status as an intermediary between the original materials and the reader.[6]In cases where digital archives merely provide access to a host of different resources at the same time, a virtue can be made of keeping traditional editorial apparatus or paraphernalia to a minimum, so that as little as possible is interposed between the reader and a transcription or image of the ‘original’. This effect of unmediated contact with the document can be enhanced by suppressing editorial activity, and by hiding both the programming work that has been involved in creating the site, and the coding that underlies the transcriptions. The benefits to the user of such digital productions are obvious: disparate archives can be virtually re-united, the researcher can interrogate the materials with the benefits of digital tools, and the images may well offer a better view of the original text than is possible by actually inspecting the original document.[7]
Nevertheless, the notion that giving researchers virtual access to original materials is sufficient by itself, is problematic, as is the conceit that this access is actually unmediated. The digitised images may seriously mis-represent the original in some sense, while the encoded transcriptions are in reality collaborative interpretations made by programmers, encoders, transcribers and editors. Downplaying such work effaces the crucial roles played by editing, and it erodes the capacity to assign credibility to the output by identifying the person or team responsible or accountable for its creation. Any well formed archive must in some sense be an edition, since one or more people have exercised skill, effort and judgement in identifying, assembling and producing the core resources. In the Newton Project, a substantial amount of editorial effort has gone into creating the infrastructure of the site, reaching copyright agreements over licensing the materials, arranging the materials into a coherent form (based on the catalogue of Newton’s papers), and creating richly encoded, accurate transcriptions. This represents a vast amount of on-going but vital editorial work that precedes the addition of even more contextual information.
The emphasis on establishing, transcribing and tagging the documentary materials is also to some extent in line with the recent emphasis within digital editing on the material document rather than on the ‘text’ — the latter understood as the meaningful script arising from the document. Some commentators have suggested that the primary focus of a digital production should be on accurately rendering all information relevant to the physical document, while the editorial work involved in interpreting the text and in articulating its relationship both to other texts by the author and to wider contexts should be deferred to a later stage. Establishing and re-presenting the documentary archive has always been the core business of the Newton Project. From the outset, the transcription and encoding of the source materials was linked to the creation of the substantial online catalogue of his non-scientific papers. This includes all relevant details extracted from the correspondence of John Maynard Keynes and Abraham Shalom Yahuda about the provenance and subsequent fate of the alchemical and religious papers following their sale at Sotheby’s in July 1936.[8]
The concentration on the document has been criticised by other scholars, who argue that editorial focus should be on the contexts and intentions underlying the creation of the text, along with the various meanings constituted by the various historical interactions with the text once it has been made available for scrutiny. From this perspective, the Newton Project evidently satisfies most of the requirements needed to be classed as a digital edition. The Project site has published a vast amount of additional primary and expository material in the form of translations, editorial notes and contextual primary sources, along with a general introduction to the overall Newton Project (of which this sentence is a part). The contextual materials on the Newton Project rival or surpass those on any other scholarly digital site in terms of scale, and include detailed and explicit descriptions of editorial policy in areas such as transcription and annotation; a comprehensive presentation of all the biographical materials written about Newton in manuscript and printed form in the eighteenth and nineteenth centuries; the Newton-related personal papers of Keynes; a large amount of textual material relating to the popularisation of Newtonianism in the eighteenth century; a series of podcasted interviews about Newton and his intellectual environs conducted in 2009-11; interpretive essays on Newton’s political and religious writings; and a full description of Newton’s library. With such a vast range of materials available for the reader or researcher, the Newton Project is clearly more than a digital edition. For that reason, it might be termed a digital research environment, though again, it would be unwise to attempt to define such an entity too precisely.
Although there is a substantial amount of contextual material on the Newton Project site, the scale of the archive also makes conventional editing extremely difficult. In addition to thousands of passages extracted from primary sources, there are hundreds of stand-alone chapters whose relationship both to each other, and to some larger ‘work’ of which they must have been a part, is still unknown. Indeed, since similarly titled chapters were promiscuously reproduced in different projects, it is hard to see what constitutes a work in these circumstances, and there is nothing close to a privileged text that could exist as a reasonable ‘copy text’. Nevertheless, the editorial team at the Project has begun the task of ordering the archive, and of ascertaining how all the parts of the whole fit together both logically and chronologically. A great deal of effort identifying similarities between concepts, sentences, paragraphs and chapters across the vast panorama of his work has already been done by the transcribers and general editors, although a comprehensive account of Newton’s working practices, including the way he re-used his own materials, must await the transcription of all of his writings. This editorial work obviously benefits from the existence of the simple search and browsing facilities already on the site.
The work required to interpret, transcribe, encode and publish the most heavily rewritten folios is immensely difficult and time-consuming, being as much as twenty times greater than for a relatively ‘clean’ page. Rough working notes from his early mathematical researches are the most difficult texts of all, and take a vast amount of skill, time and effort to transcribe, encode, check, and publish online. This has been accomplished in such a way that they can be seen by researchers inspecting the text in one of about ten different versions of the major browsers currently in use. Other pages present different problems. In the following heavily encoded example, from Newton’s ‘Waste book’, his step-father’s much older writings are at the top of the page while Newton has re-used the paper for a completely different purpose.

Although the Barnabas Smith text is located elsewhere on the site (and is described in section 3.A.vi below), the Newton material appears in diplomatic form on the Newton Project as
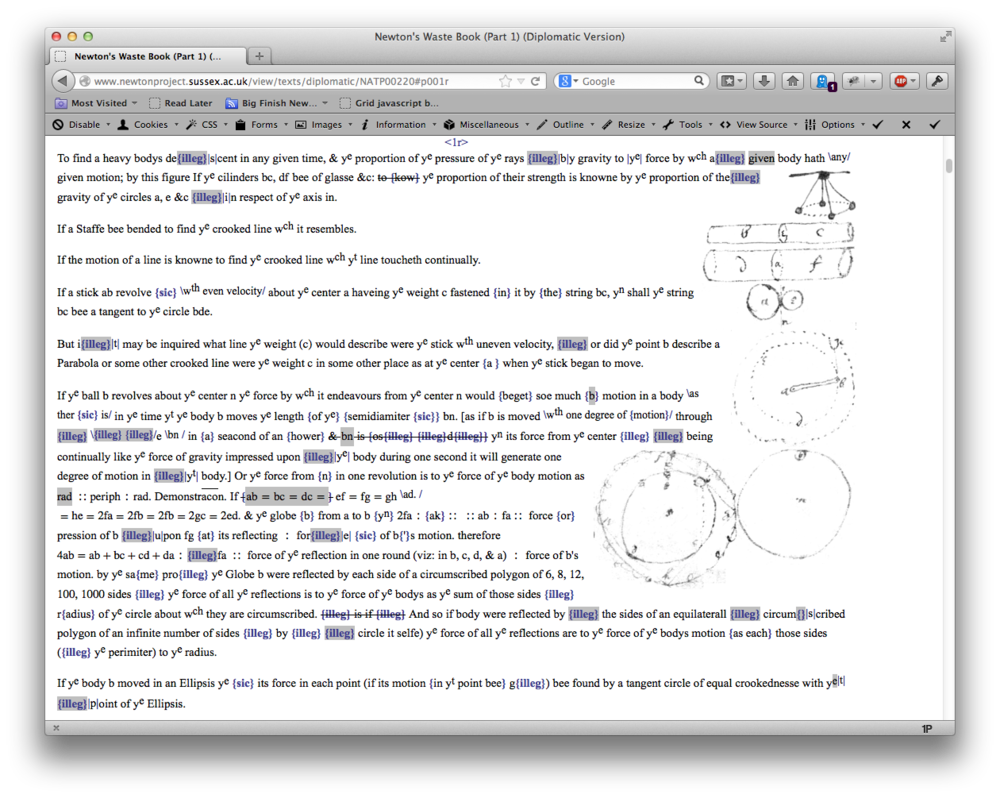
while the underlying coding has been represented as
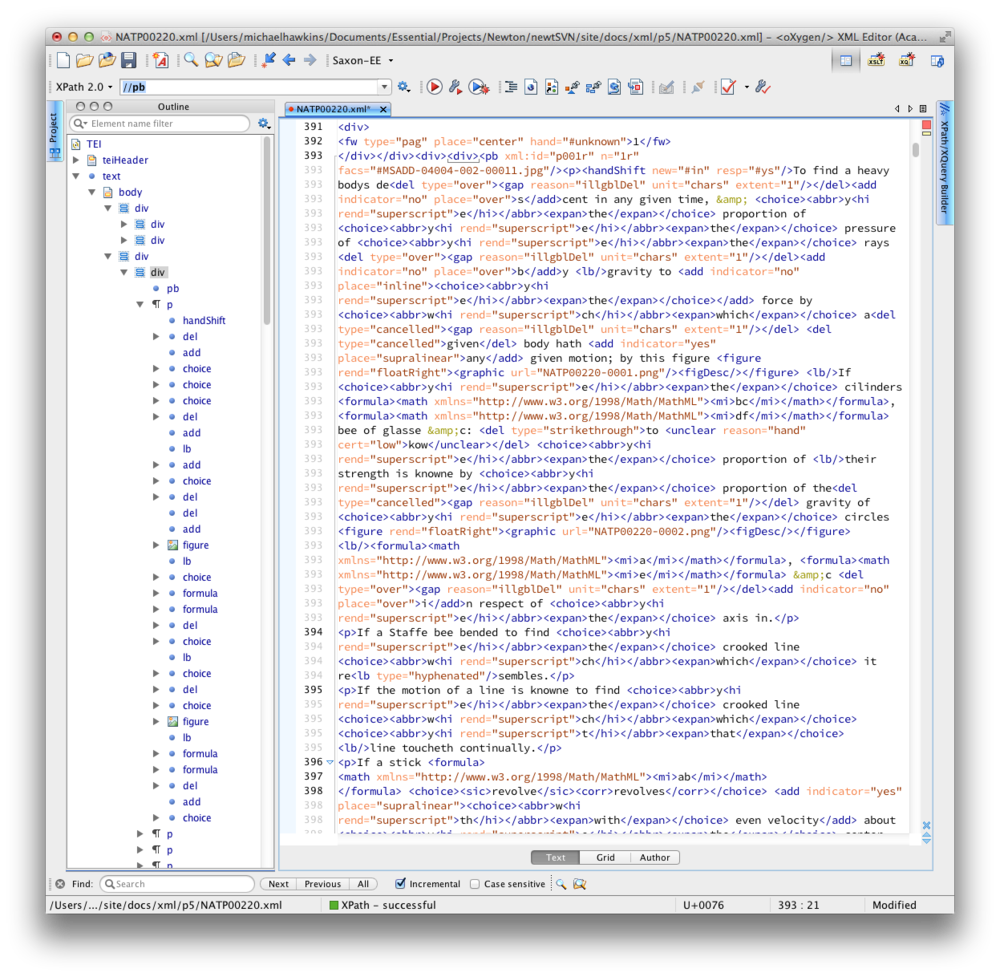
Until 2011, the only means of transcribing and checking transcriptions was to prepare preliminary transcriptions from microfilm, and then to travel to places where the documents are now housed in order to check ‘against the original’. The majority of the religious documents are now based at the NLI, and funding constraints made it difficult to spend more than a few weeks in Jerusalem to check the transcriptions against the original. The bulk of the transcriptions made prior to 2009 were prepared from the Chadwyck-Healey microfilm of Newton’s papers that was released in 1991. This was itself almost wholly based on prior sets of microfilm prepared by Cambridge University Library, the Jewish and National University Library (Hebrew University), and King’s College Cambridge. In 2009 the Newton Project team was given access by the Chymistry of Isaac Newton Project to digitised (greyscale) images of photocopies that were prepared in the 1970s for Richard S. Westfall. These are far superior to the Chadwyck-Healey microfilms, being more legible and including pages that were missed in subsequent efforts to capture images of the papers, either through carelessness or because they had been stolen in the meantime.
Since 2011 we have had access to high quality colour images of the entire Newton archives at CUDL and the NLI. In the case of more ‘polished’ documents, in which Newton made few changes from one version to the next, the greyscale images are barely inferior to the colour images. The colour images come into their own, however, in transcribing very heavily overwritten folios, of which there are hundreds. These are the sorts of documents whose contents are of much more interest to the specialist interested in the minute development of Newton’s ideas, but whose messy complexity is impossible to capture in a print edition. Aside from the damage to the document that is perpetrated by continually inspecting it from different angles (or in different lights), manipulation of the colour images can allow more information to be made available than is possible by directly handling the original. In the case of the page from the ‘Waste book’ reproduced above, for example, some of the text is too faded to be seen with the naked eye, but it is now clearly visible by enhancing the image file.
Now that the Cambridge and Jerusalem images are freely accessible online, the Newton Project has begun to provide links to them at the document level. As a result, editors and readers can now see images alongside originals, a facility that utterly transforms the nature and usefulness of the site. At present this can only be done by opening up two separate windows, which is a practical if less than ideal solution, but researchers and editors can now check the quality of the work produced on the project, and suggest or effect corrections. The capacity to see high quality images of the originals brings problems alongside opportunities. As already stated, we now have the ability to produce highly accurate transcriptions of original documents without travelling to the actual institutions where these are housed. On the downside, what was once unreadable on the microfilms we were using is now visible, and a great deal of work has been performed since 2009 using the colour images to correct those marks previously labelled ‘illeg.’
It is obvious that the task of editing these texts in any conventional sense is impossible for any single scholar, and the complete reconstruction of Newton’s archive will require many more years along with the handiwork of many individuals, most of whom will not have been trained as scholars. The production of an online edition of this magnitude places immense technical and administrative burdens upon the editor and editorial team, which go beyond what is demanded of traditional print productions. Conventional editing does not require the editor to sustain the digital infrastructure while the project materials are being created, and it certainly does not require the editor to be involved in the maintenance and development of the edition after a certain date at which project is supposed to have ended. In any case, funders do not give open-ended support to these projects without some demand that some or all of the texts will have been published online by a certain moment.
Publishing the Newton papers online, and adding sophisticated searching and browsing facilities makes the task of reintegrating these documents at least conceivable, and practically possible. Nevertheless, it is probable that only the concerted effort of many people will allow the resource to realise its full potential. The fact that the materials are freely available online opens up the genuine possibility of using the skills of readers to correct transcription errors. The opportunity to make use of the power of the crowd — that is, of many of the tens of thousands of visitors who come to the site each year — will almost certainly need to be realised in the next few years. Much editorial effort during this period will go into creating the infrastructure that will allow readers to contact editors alerting them to errors, or better still, to become trusted editors in their own right. Indeed, many readers will aspire to and be capable of much more than correcting transcription errors, and the long-term sustainability and viability of the project may well be guaranteed by adopting a partnership model in which academics co-own the site with non-academics.
[1] Since 2004 the task of producing an online edition of Newton’s alchemical papers has been ably performed by the University of Indiana’s Chymistry of Isaac Newton project, directed by Prof. William Newman. We would particularly like to thank Grant Young at CUDL for his work on the JISC ‘Windows on Genius’ project, and Prof. Stephen Snobelen at King’s College for making the encoded transcriptions produced by Newton Project Canada available to the Newton Project.
[2] About 90% of his pre-1700 scientific and mathematical correspondence is now online. Many other notes and drafts, particularly those relating to the recasting of the Principia, have never been published but we intend to transcribe and release these over the next 4-5 years. Altogether, we estimate that about 1.4 million words from his writings in mechanics, physics and mathematics (now in the Portsmouth and Macclesfield papers at Cambridge University Library) remain to be transcribed.
[3] See R. Iliffe, "Digitizing Isaac: The Newton Project as an electronic edition of Newton’s papers," in J.E. Force and S. Hutton, eds, Newton and Newtonianism: new studies, (Kluwer, 2004), 43-72.
[4] I make a pragmatic distinction between a ‘reader’ and a ‘researcher’. The former is likely to be interested in accessing the transcribed text in a more traditional or linear fashion, while the latter is interested in a number of different questions and in using the site in a very different and much more complex way.
[5] The term ‘document’ refers to the original material object on which transcriptions are based, while the ‘text’ refers to an edited interpretation of that document. The latter, in conventional editing terms, might well be an amalgam or composite made up of different drafts or editions. For general comments on digital editions see Iliffe, ‘Digitizing Isaac,’; P. Shillingsburg, From Gutenberg to Google, (Cambridge, 2006), esp. 2-18, 34-5, 81-97, 144-57 and 165-76; H. Gabler, "Theorizing the scholarly archive", Literature Compass 7/2 (2010), 43-56; P. Fyfe, "Electronic errata: digital publishing, open review, and the futures of correction," in M.K. Gold ed., Debates in the Digital humanities, (St. Paul, 2012), and P. Robinson, "Towards a theory of digital editions," Variants 10 (2013), 106-27.
[6] These features of the conventional print can be summarised as (a) the linear order and physicality of the book; (b) the presence of a named editor who has vouched for the accuracy of the textual rendition and who has added various forms of ‘apparatus’; and (c) the presence of a ‘publisher’. One might add the facts that (d) such books have ISBN numbers (or equivalents) and thus have a unique ISO identity, and (e) they are citable resources with either the name of the author or of the editor coming first. Finally, whether one likes it or not, (f), the fact that such works cost money also confers additional value on the product.
[7] From the point of view of the archivist or curator, there is no further damage to the physical documents.
[8] For the notion of the ‘work’, which arises from a particular combination of texts, see P. Eggerts, Securing the Past.: Conservation in Art, Architecture and Literature (Cambridge, 2009) and Robinson, ‘digital editions’, 110-20.